Serverless Diary: An Experts Guide to Reducing Serverless Waste

I. Introduction
Serverless computing benefits allow us to create agile and iterative architectures capable of being delivered rapidly than ever before. This benefits the business as the time to market is drastically reduced. Especially in the last one and a half years of the pandemic, we have seen the importance of speed to market and organizations delivering software within day’s if not weeks, leveraging the speed factor that serverless architecture offers. But there are few things that one should be watchful of the iterating architecture, where serverless designs tend to stack up various AWS services, which could result in hundreds of serverless functions, messaging queues, storage buckets to support within a year or two.
The focus of this blog is to discuss and share ideas on how to make smart choices while still adhering to a microservices architecture style using AWS as the public cloud provider.
II. The Challenge
Ensure the architecture choices considers good balance and harmony across all phases of the project delivery model of
Design — Build — Run
Day 0 — Day 1 — Day 2
It’s increasingly important in the current fast-paced iterative cycle of Design, Build and Run, that the architectural choices equally consider the design implications on day2 operations/run phase and how the evolving state would be managed and run. An architect should strive to find a good balance of business needs required today and thinking how the solution would extend to scale and evolve as per business requirements. While implementing serverless architecture style for green-field projects, it’s tempting to design and spin up new lambdas, gateways, queues bucket for every single requirement. This at first seems to align with the single responsibility principle, but within a year or so quickly turns into something complex to manage and scale.
This blog is about increasing awareness and asking you to pause for a minute and think about re-use and how making simple design choices while laying the initial foundation can help ensure success across Design, Build & Run phase.
Why is the concept of re-use important for serverless architecture?
- More infrastructure component means more maintenance. This includes serverless components like SQS, API Gateways, etc where extra infrastructure doesn’t necessarily equate to direct additional cost. But one still ends up tracking all components, building alerting, metrics, health checks, and maintaining separate operational run books for them, which is the in-direct cost for supporting day2 activity within operations.
- All good designs avoid “A Single Point of Failure”. More infrastructure components imply more chances and permutations of failure points in the design. Hence additional effort and infrastructure are required to ensure business continuity. More infrastructure invariably equates to increased complexity.
- A system should be architected considering service level quotas and limits. This helps in forecasting if the business grows or a product suddenly becomes famous, how much the serverless architecture can scale before it hits the account limits of AWS components. For example, by default, you can create 100 S3 buckets in each of your AWS accounts. This account bucket limit can be increased to a maximum of 1000 buckets (at time of writing this blog). For bigger organizations or products, it’s quite easy to hit these limits if the initial design isn’t mindful of these service quotas.
III. The Solution
The best way to bring life to the challenge described above is to work through an example.

Let us understand the steps and approach of the initial design from figure 1:
Initial Design — Step 1 — Prepare and Publish Message
Assuming the Router lambda gets invoked (either synchronously or asynchronously), It parses the payload received and PUT’s a message on the SQS Queue1 or Queue2 determined by the value of x.
Initial Design — Step 2 — Prepare and Publish Message
Both Queue-1-receiver & Queue-2-receiver lambdas are configured as destinations for SQS Queue1 & Queue2. So Based upon which queue receives a message, the corresponding lambda gets triggered, which parses the payload. After parsing the payload it uses the information to GET an object from the s3 bucket specific to the 3rd party application. Following this, it POST’s the updated payload to the corresponding 3rd party application. If there are any errors, messages are retried x number of times before the messages move to the SQS DLQ.
Now let’s look at the Re-factored design from figure 1:
Re-factored design — Step 1 — Prepare and Publish Message
Assuming the Router lambda gets invoked (either synchronously or asynchronously), It parses the payload received and structures the message to include header and payload. The header contains metadata that indicates the target 3rd party application for the message. Router lambda constructs the header and payload, based upon the value received for x and PUT’s a message on the SQS Queue.
Re-factored design — Step 2 — Prepare and Publish Message
Queue-receiver lambda is configured as a destination for SQS Queue. So Based upon the value of “header.eventType”, the lambda decides s3 prefix to lookup information from, and then POST’s an updated payload to the corresponding 3rd party application. If there are any errors, messages are retried x number of times before the messages move to the DLQ.
Summary
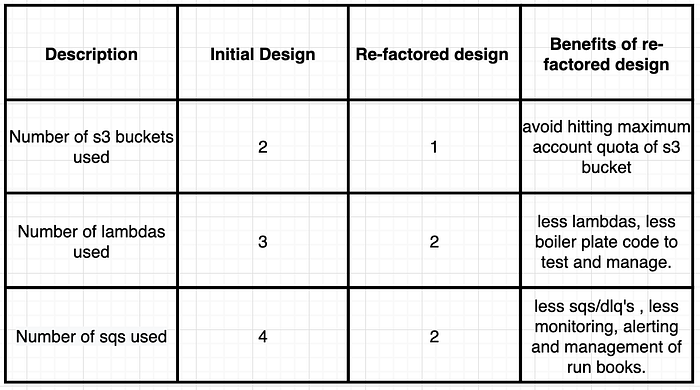
This is a partial flow I have picked as an example, and we already see this design results in less serverless infrastructure components and promotes reuse with less code to manage. It is a typical serverless pattern, and when you scale this pattern, the components involved multiply.
I haven’t focussed on the SQS DLQ and how minimizing those makes operations part easy of replaying messages as and when required. I will cover this in my future blog.
IV. 3 Key Takeaways
- Be mindful of principles discussed in this blog, but stray from falling into the anti-pattern of designing micro-monoliths. Re-use should respect SOLID principles and hence only group components which belong together.
- If you are re-using SQS, be mindful that the visibility timeout of SQS should be more than the lambda timeouts. This implies if queues are being re-used, the corresponding lambda triggers must share the same timeout.
- When re-using S3 buckets via the use of prefixes(folders), ensure you are constructing granular level IAM policies using folder level permissions.
If this post was helpful, please click the clap 👏 button below a few times to show your support for the author 👇